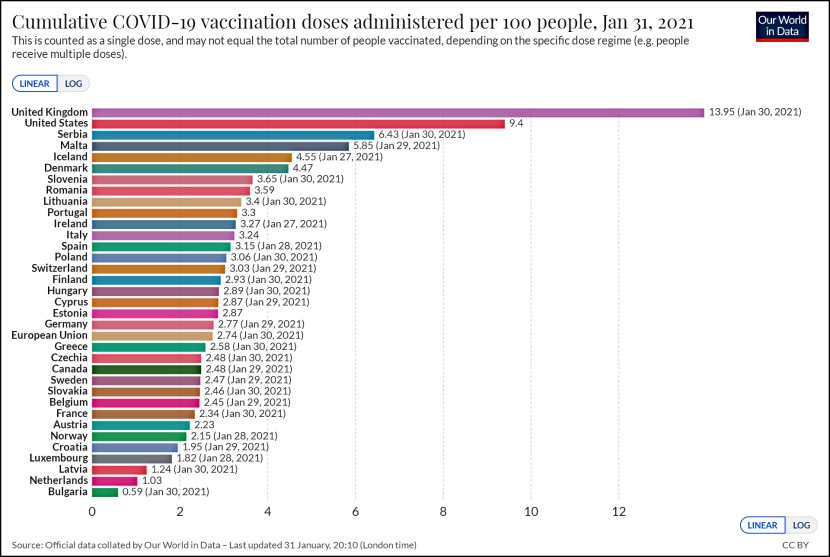
Dana Goldstein writes today that very shortly computers are going to lose their ability to efficiently score student writing test samples. Why? Because new tests are going to be more fact-based. Instead of asking students to ruminate on “the benefits of laughter,” they’ll ask students to read a nonfiction passage and write something about it. “Since robo-graders can’t broadly distinguish fact from fiction,” Dana says, they won’t be very good at scoring these kinds of essays.
My first thought when I read this was “IBM’s Watson cleaned Ken Jennings’ clock on Jeopardy! Don’t tell me computers can’t distinguish fact from fiction.” But then I was put in my place:
Brown University computer scientist Eugene Charniak, an expert in artificial intelligence, says it could take another century for computer software to accurately score an essay written in response to a prompt like this one, because it is so difficult for computers to assess whether a piece of writing demonstrates real knowledge across a subject as broad as American history.
Oh man. I don’t have anything like Mitt Romney’s wealth, and I know Charniak’s the expert, but I’m still willing to bet him $10,000 that a computer will be as good as a human at scoring fact-based high school essays by — oh, let’s say 2022 just to make it sporting. I figure there’s at least a chance I could lose that bet. 2032 would be a no-brainer. Later in the piece, after noting that new techniques have produced quantum leaps in language processing before, Dana weighs in on this:
A paper by ETS’s Derrick Higgins and Beata Beigman Klebanov points to a potential path forward: using Web databases of human knowledge, like online encyclopedias and news repositories, to check how factual and intellectually sophisticated an essay truly is.
….[One] program, called ReVerb, can recognize about one-third of the “facts” writers present on such topics, such as the century in which Chaucer lived (the 14th) and Einstein’s most famous scientific contribution (the Theory of Relativity)….Currently, however, computers struggle with determining how trustworthy various Web sources are, and they can’t weigh or synthesize competing claims from good sources.
Yeah, well, a lot of humans have this problem too, and I’ll bet H. siliconis overcomes it way before H. sapiens does. We haven’t made a helluva lot of progress on this front over the past few thousand years.
Anyway, you’re all probably tired of hearing me harp about this. Still, I’ll put my money on the computers. They’re getting better a lot faster than most of us think.